Statistics
A Math? A Science? An Art? Or Something Else?
Statistical Warning


Statistics

With an increasing use of data to make decisions, Statistics has been essential for processing large amounts of data to byte-size information
Statistics is also known as
Data Science
Machine Learning
Artificial Intelligence
So for today, we’re asking: what is Statistics?
What is it?
Math

Science

When it fails?!?!

Statistics Mantra - George Box

All models are wrong,
some are useful!
Probability Models

Model observations that follow a new data generating process
Understand its properties
Develop new probability distributions
Known as Probability Theory
Researcher is a Probabilist or Mathematical Statistician
Data Analysis
Model data with a known probability model
Account for sources of variation and bias
Account for violations of independence and randomness
Known as Statistician or Data Scientist

Another Word Cloud

Conducting Inference
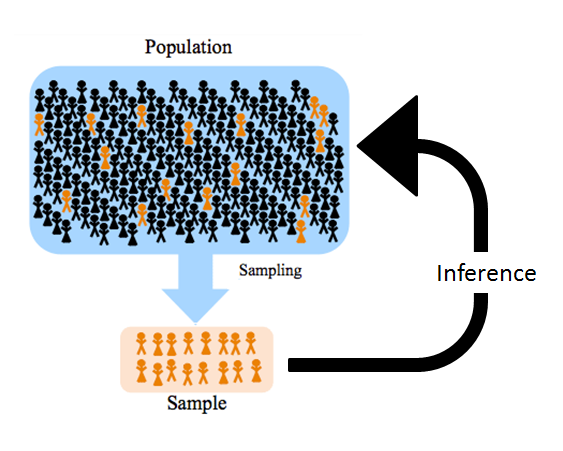
What if we cannot construct the distribution?!?!

We bring out the Monte Carlo methods!
So, what is Statistics?

For you baby, I’ll be anything
What’s happening
Survival and Longitudinal

Random Effects

Missing!?



Questions


What’s Statistics without a little …

Frequentists

Bayesians

What am I (and people that have lives)?

Whatever gets the job done!
There is more, much more, but I will say this, in my statistical journey

www.inqs.info
isaac.qs@csuci.edu